



声明:本网站所有内容均为资源介绍学习参考,如有侵权请联系后删除

课程大纲
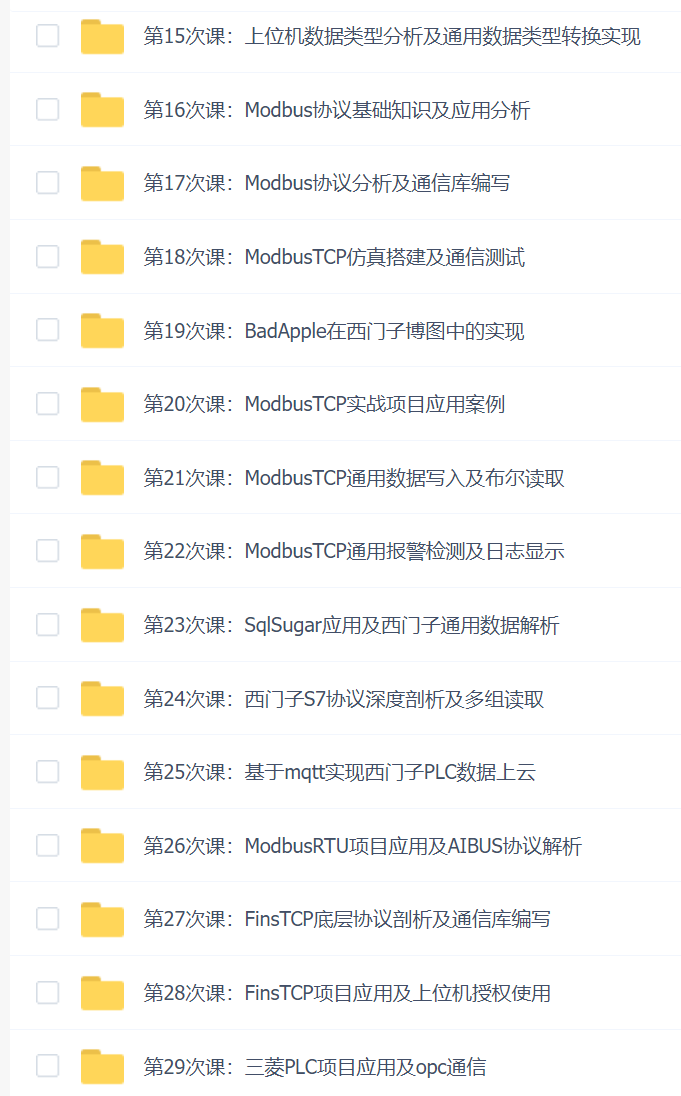
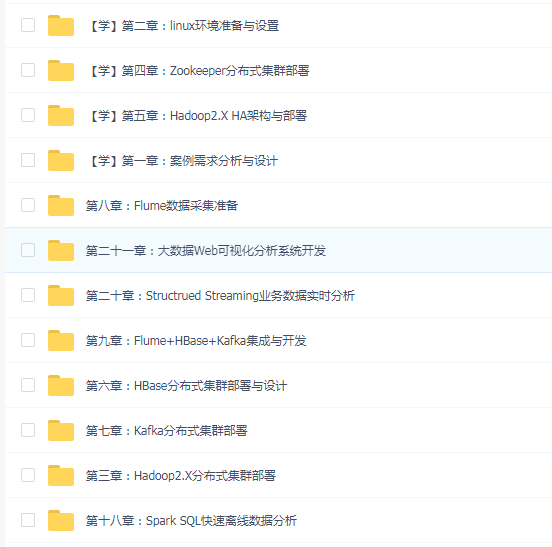
第一章:案例需求分析与设计
1. 全套课程内容概述
2. 案例需求分析
3. 系统架构设计
4. 系统数据流程设计
5. 集群资源规划设计
第二章:linux环境准备与设置
1. Linux系统常规设置
2. 克隆虚拟机并进行相关的配置
3. 对集群中的机器进行基本配置
第三章:Hadoop2.X分布式集群部署
1. Hadoop2.X版本下载及安装
2. Hadoop2.X分布式集群配置
3. 分发到其他各个机器节点
4. HDFS启动集群运行测试
5. YARN集群运行MapReduce程序测试
6. 配置集群中主节点到各个机器的SSH无密钥登录
第四章:Zookeeper分布式集群部署
1. Zookeeper版本下载及安装
2. 分布式集群配置及参数介绍
3. Zookeeper服务启动及测试
第五章:Hadoop2.X HA架构与部署
1. HDFS-HA架构原理介绍
2. HDFS-HA 详细配置
3. HDFS-HA 服务启动及自动故障转移测试
4. YARN-HA架构原理介绍
5. YARN-HA 详细配置
6. YARN-HA 服务启动及自动故障转移测试
第六章:HBase分布式集群部署与设计
1. 下载HBase版本并安装
2. 分布式集群的相关配置
3. 启动依赖于Zookeeper和HDFS的两个服务
4. 通过shell测试数据库
5. 日志信息存储需求分析及表的创建
第七章:Kafka分布式集群部署
1. 下载Kafka版本并安装
2. Kafka集群配置
3. 启动Kafka依赖于Zookeeper的服务并进行测试
第八章:Flume数据采集准备
1. Flume节点服务设计
2. Flume版本下载安装
3. Flume agent-1采集节点服务配置
4. Flume agent-2采集节点服务配置
第九章:Flume+HBase+Kafka集成与开发
1. 下载Flume源码并导入Idea开发工具
2. 根据业务需求做采集入库的程序设计
3. 自定义SinkHBase程序开发
4. idea程序打包并部署
5. 官方Flume与HBase集成的参数介绍
6. Flume agent-3聚合节点与HBase集成的配置
7. 官方Flume与Kafka集成的参数介绍
8. Flume agent-3聚合节点与Kafka集成的配置
第十章:数据采集/存储/分发完整流程测试
1. idea工具开发数据生成模拟程序
2. 编写启动Flume服务程序的shell脚本
3. 启动Flume采集相关的所有服务
4. 编写脚本并启动Flume agent三台采集节点服务
5. 编写Kafka consumer执行脚本并运行
6. java开发业务数据生成模拟器
7. 运行模拟程序并通过HBase shell检查数据
第十一章:MySQL安装
1. 配置linux本地镜像源
2. linux联网安装mysql数据库
3. myql设置用户连接权限
4. 分析业务需求并设计表结构
5. 创建数据库和与业务相关的表
第十二章:Hive与HBase集成进行数据分析
1.Hive 概述
2.Hive 架构设计
3.Hive 应用场景
4.Hive 安装部署
5.Hive与MySQL集成
6.Hive 服务启动与测试
7.根据业务创建表结构
8.Hive与HBase集成进行数据离线分析
第十三章:Cloudera HUE大数据可视化分析
1.Hue概述
2.Hue安装部署
3.Hue基本配置与服务启动
4.Hue与HDFS集成
5.Hue与YARN集成
6.Hue与Hive集成
7.Hue与MySQL集成
8.Hue与HBase整合
9.对采集的数据进行可视化分析
10.Hue使用的经验总结
第十四章:Spark2.X环境准备、编译部署及运行
1.Spark 概述
2.Spark 生态系统介绍
3.Spark2.X学习注意事项
4.Spark2.2源码下载及编译
5.Scala安装及环境变量设置
6.Spark2.2本地模式运行测试
7.Spark服务WEB监控页面
第十五章:基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装
2.IDEA Maven工程创建与配置
3.开发Spark Application程序并进行本地测试
4.打Jar包并提交spark-submit运行
第十六章:Spark2.X集群运行模式
1.Spark几种运行模式介绍
2.Spark Standalone集群模式配置与运行
3.Spark on YARN集群模式配置与运行
第十七章:Spark2.X分布式弹性数据集
1.三大弹性分布式数据集介绍
2.Spark RDD概述与创建方式
3.Spark RDD五大特性
4.Spark RDD操作方式及使用
5.DataFrame创建方式及功能使用
6.DataSet创建方式及功能
7.数据集之前的对比与转换
第十八章:Spark SQL快速离线数据分析
1.Spark SQL概述及特点
2.Spark SQL服务架构
3.Spark SQL与Hive集成(spark-shell)
4.Spark SQL与Hive集成(spark-sql)
5.Spark SQL之ThirftServer和beeline使用
6.Spark SQL与MySQL集成
7.Spark SQL与HBase集成
第十九章:Spark Streaming实时数据分析
1.Spark Streaming功能介绍
2.NC服务安装并运行SparkStreaming
3.Spark Streaming服务架构及工作原理
4.Spark Streaming编程模型
5.Spark Streaming读取Socket流数据
6.Spark Streaming结果数据保存到外部数据库
7.SparkStreaming与Kafka集成进行数据处理
第二十章:Structrued Streaming业务数据实时分析
1.Structured Streaming 概述及架构
2.Structured Streaming 编程模型
3.实时数据处理业务分析
4.Stuctured Streaming 与Kafka集成(一)
5.Stuctured Streaming 与Kafka集成(二)
6.Stuctured Streaming 与MySQL集成
7.基于结构化流完成业务数据实时分析(一)
8.基于结构化流完成业务数据实时分析(二)
9.基于结构化流完成业务数据实时分析(三)
第二十一章:大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计
2.下载Tomcat并创建Web工程
3.Web系统数据处理服务层开发
4.基于WebSocket协议的数据推送服务开发
5.基于Echart框架的页面展示层开发(一)
6.基于Echart框架的页面展示层开发(二)
7.工程编译并打包发布
8.启动各个服务并展示最终项目运行效果